














New AI-Driven Discovery Experience
Today, we are excited to give you a preview of the result of that work with the release of the new discovery experience in the Feedly Lab app (Experience 06).

New AI-Driven Discovery Experience
Today, we are excited to give you a preview of the result of that work with the release of the new discovery experience in the Feedly Lab app (Experience 06).
We love the Web because it is an open and distributed network that offers everyone the freedom and control to publish and follow what matters to them.
We also love the web because it has enabled a new generation of content creators (Ben Thompson, Bruce Schneier, Tina Eisenberg, Seth Godin, Maria Popova, etc.). Those independent thinkers continuously explore the edge of the known and share insightful and inspiring ideas with their communities.
Connecting people to the best sources for the topics that matter to them has been core to our mission since the very start of Feedly.
But discovery is a hard problem. The web is organic, a reflection of the global community’s changing needs and priorities. There are millions of sources across thousands of topics and we all have a different appetite when it comes to feeding our minds.
About twelve months ago, we created a machine learning team to see if the latest progress in deep learning and natural language processing could help us crack this nut.
Today, we are excited to give you a preview of the result of that work with the release of the new discovery experience in the Feedly Lab app (Experience 06).
Two thousand topics
The first discovery challenge is to create a taxonomy of topics.
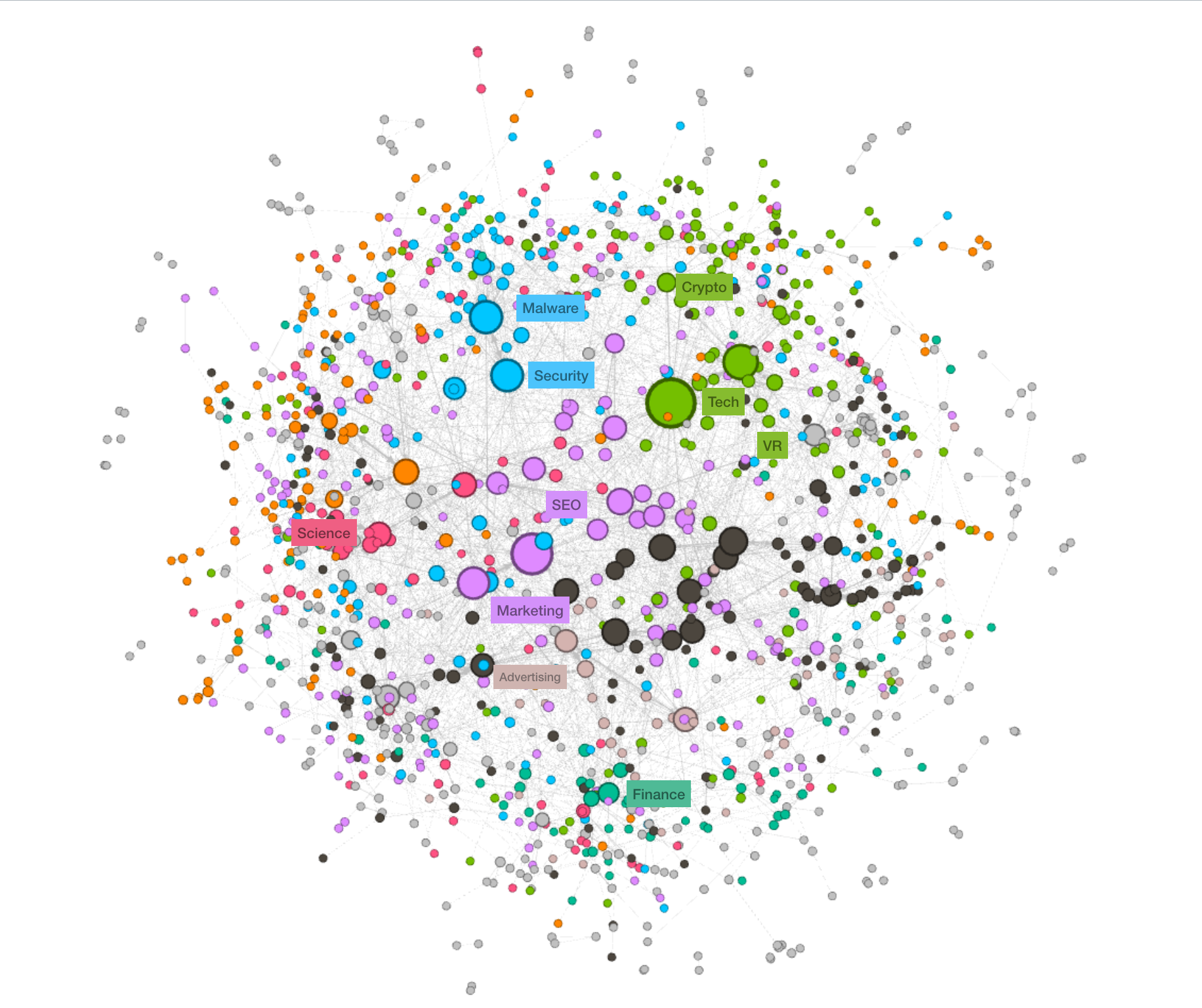
You can think of Feedly as a rich graph of people, topics, and sources. To build the right taxonomy, we started with the raw data on all of Feedly’s sources. We had to create a model to clean, enrich, and organize that data into a hierarchy of topics. Learn more about the data science behind this.
The result is a rich, interconnected network of two thousand English topics. And it’s mapped well with how people expect to explore and read on the Web.
Some topics are broad: tech, security, design, marketing. Some are very niche: augmented reality, malware, typography, or SEO.
On the discovery homepage, we showcase thirty topics based on popular industries, trends, skills, or passions. You can access all of the topics in Feedly via the search box.
The fifty most interesting sources
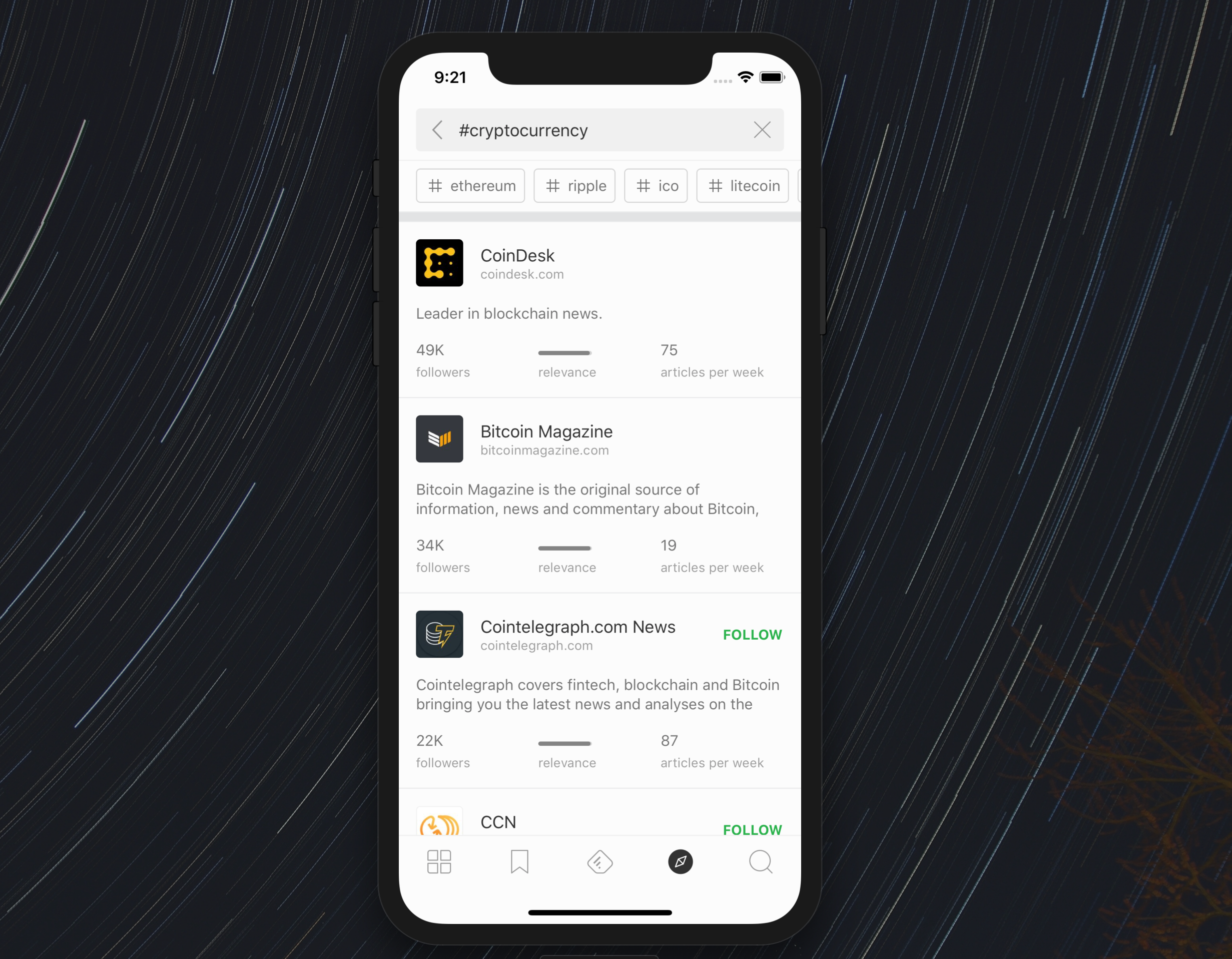
The second discovery challenge is to find the fifty most interesting sources someone researching any topic might want to follow.
Ranking sources is hard because not all sources are equal. In tech as an example, you have mainstream publications like The Verge or TechCrunch, expert voices like Ben Thompson, and lots of B-list noisy sources which don’t add much value.
In addition, for niche topics like virtual reality, some sources are specific to VR while others cover a range of related topics.
To solve this challenge, we created a model which looks at sources through three different lenses:
- follower count
- relevance (how focused is the source on the given topic)
- engagement (a proxy for quality and attention)
The outcome is new search result cards. You can explore the fifty most interesting sources for a given topic and sort them using the lens that is most important to you.
Neighborhoods
One of the benefits of the new topic model is that the 4,000 topics are organized in a hierarchy. This makes it easy for you to zoom in or out and explore many different neighborhoods of the Web.
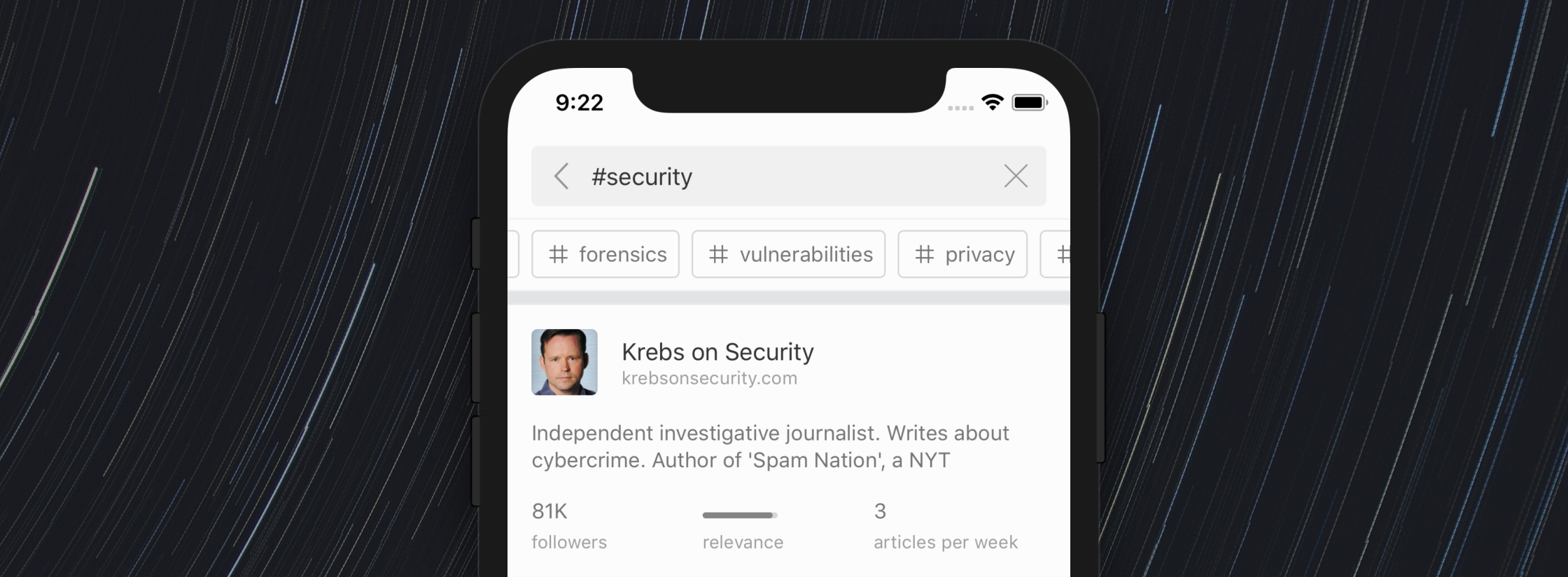
For example, from the cybersecurity topic, you can jump to a list of related topics that let you dig deeper into malware, forensics, or privacy.
One more thing…
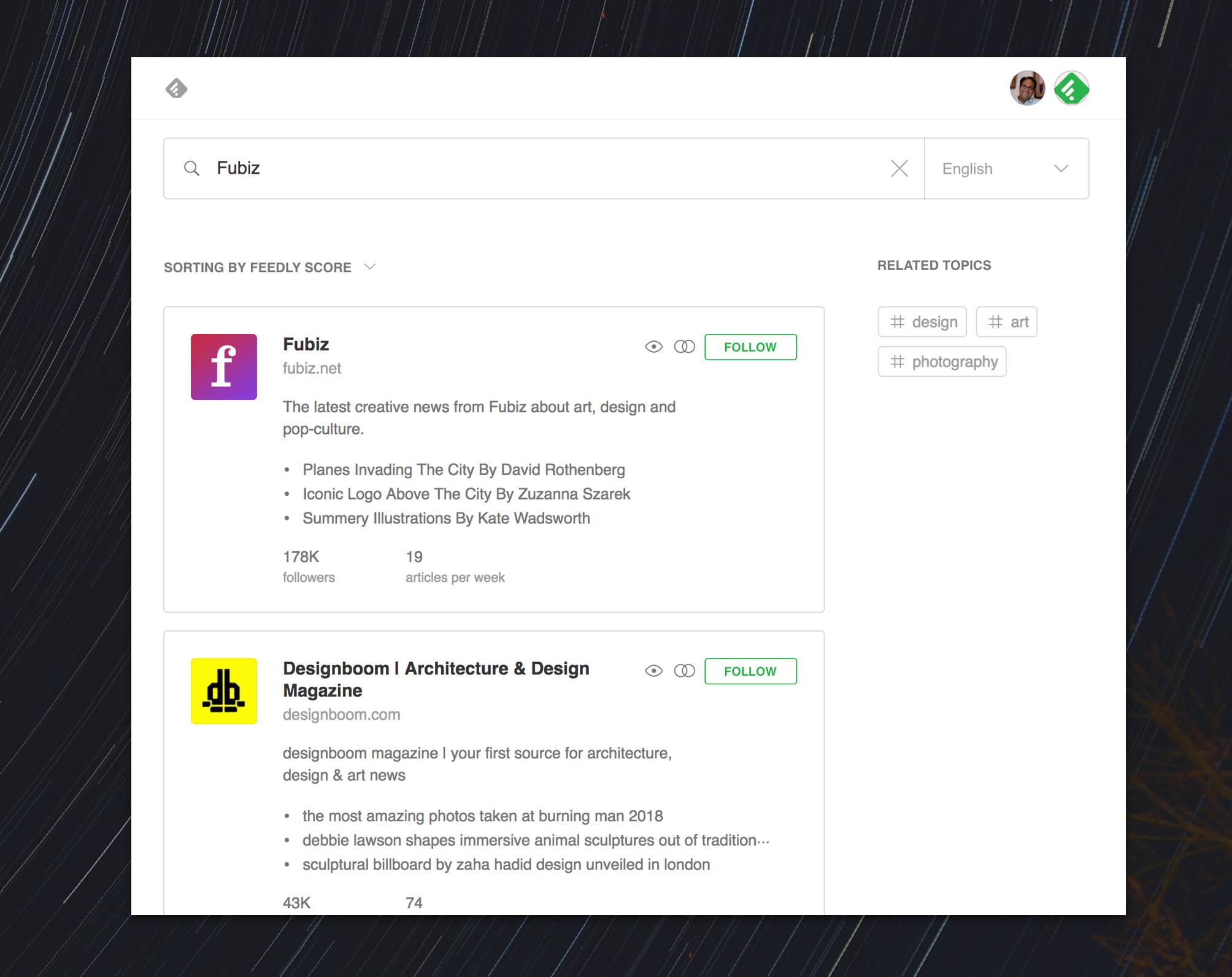
We have done a lot of research over the last four years to understand how people discover new sources. One insight we learned is that people often co-read certain sources. For example, if you are interested in art, design, and pop culture and you follow Fubiz, there is a high chance that you also follow Designboom.
With that in mind, we spent some time creating a model that learns what sources are often co-read. The idea is that a user could enter a source that they love and discover another source they could pair it with.
You can learn more about the machine learning model (we call it feed2vec) powering this experience through the article Paul published here.
As a user, you can access this feature by searching in the discover page for a source you love to read. The result will be a list of sources which are often co-read with that source.
Thank you!
I would like to thank Paul, Michelle, Mathieu, and Aymeric for the great research work they did to take this project from zero to one. People who have tried to tackle discovery know that it is a very hard challenge and the results of this project have been very impressive.
We would also like to thank the community for participating in the Battle of the Sources experiment. Your input was key in helping us learn how to model the source ranking. We are going to continue to invest in discovery and we look forward to continuing to collaborate with you.
We would also like to thank Dan Newman, Daron Brewood, Enrico, Joey, Lior, Paul Adams, Ryan Murphy, and Joseph Thornley from the Lab for reviewing an earlier version of this article.
What's Your Reaction?










